| << 2026年02月 >> | ||||||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
新着記事
最近のコメント
月別
カテゴリ
2026.02.28 23:58
CNNってこういう感じで良いのかな?
・CNNのバックプロパゲーションを考える。
・要するにフィルタを移動させて得た画像データを縮小したものに対する補正値が戻ってくるわけだ。
・たとえばフィルタを3x3として、2x2の4ドット分を1ドットに縮小して、このドットのデータが全結合ニューラルネットに入るという構成を考える。
・一応、今の理解では順方向の操作は
1)元画像の4x4の四角い領域を3x3の除き窓で覗く。
2)左上、右上、左下、右下の4箇所の3x3の領域について、それぞれの画素データと、対応する位置のフィルタのデータを掛け算して和を取る。(イメージとしては、照度センサの前にパターンの描かれたシートを貼り付けもので明るさを測っているようもの)
たとえば
フィルタ側を
F0 F1 F2
F3 F4 F5
F6 F7 F8
というデータ、画素側が
G00 G01 G02 G03
G04 G05 G06 G07
G08 G09 G10 G11
G12 G13 G14 G15
として、フィルタが左上なら
F0xG00 F1xG01 F2xG02
F3xG04 F4xG05 F5xG06
F6xG08 F7xG09 F8xG10
となるわけで、これら9つを足したものに更にバイアスを足したものをつくる(仮にSUM00とかする)
3)窓を元画像全体に渡って1ドットずつ(1枠ずつではなく)移動させると
SUM00 SUM01 SUM02 SUM03・・・
SUM10 SUM11 SUM12 SUM13・・・
SUM20 SUM21 SUM22 SUM23・・・
・・・・
となる
4)こうして得られたものをたとえば縦横2ドットずつまとめるなら
SUM00 SUM01 SUM02 SUM03
SUM10 SUM11 SUM12 SUM13
といった4画素分ずつまとめて、たとえばこの中の最大値を採用して4ドットを1ドットにする。これがプーリング層と呼ばれるものの役割ということらしい。
5)全フィルタについて同じようなことをする。ここまでの例なら
元画像の画素数÷4×フィルタの枚数
個のデータ列になる。これを全部まとめて全結合ニューラルネットに食わせる。
という具合。
・さて、このときたとえば、左上の4つをまとめたものに対してバックプロパゲーションで戻ってきた値というのは、SUM00,SUM01,SUM10,SUM11の4つに共通して使われる。
・ただ、「誤差の責任」はプーリングした時に採用したもの・・・たとえばSUM00だけとか、SUM11だけとか・・・にしかないので、バックプロパゲーションで調整するのにつかうのは「採用したもの」だけ
・たとえばSUM00が採用されたものだとすると、これは
F0xG00 F1xG01 F2xG02
F3xG04 F4xG05 F5xG06
F6xG08 F7xG09 F8xG10
の和だったわけで、とすると「誤差の責任の割当」は全結合のバックプロパゲーションと同じ。全結合層から戻された値をVback、学習率をLRとすれば、たとえばF00の補正はF00 ー= Vback*LR*G00てな具合。
・これをプーリング層出力の(元画像画素数÷4)個分処理するとフィルタ1個分が補正される。で、全フィルタ数分やれば全部のフィルタが補正される。以下は繰り返しである。
・ただ、加算されていく数が多いので発散しかねないから、全部足した後でプーリング層出力の数で割って平均を取ると良いんだろうな。
・たぶん、こんな感じで大きく外してはいないと思うのだけど。もう一回本当にそうなのか確認しておこう。
2026.02.27 16:53
CNNを試すか。ちょっと予備学習
・まぁそんなところで、全結合ニューラルネットワークの方はほぼ作り方がわかった(気がする)。活性化関数を色々変わったものに変えたり、ウェイトやバイアスの変化のさせ方を弄ったりしても面白いことが起きるのだろうけど。
・というところで、mnistで遊んでいたためか、GCC(Gemini/Chatwork/Copilot)君からは「CNNやってみない?」というお題がきた。
・全結合だと画像が上下左右に動いたりしたときに全く違うデータとして扱われてしまうので、これをまとめてしまおうという仕掛けがCNNということらしい。
・CNNはConvolutional Neural Networkの頭文字をとったもので一般的には「畳み込みニューラルネットワーク」と訳されているけど、Convolutionalのvolutionって回転を意味してなかったっけ?と辞書を引いたらほら案の定。
・「くるくる撒いた状態、渦巻き、込み入った状態、複雑」っていう感じで、なんとなく糸巻き的なものをイメージするようなネーミングではある。
・やっていることをちょっと検索してみた今現在の理解はこんな感じ
1)に小さい四角い窓(2X2とか3X3とか)を用意して、この中で重み付けをする(フィルタと呼んでいる)。すると、例えば横線と右斜め下がりの線とかの特徴があるとみなせる部分が強く現れる。(真っ白でも反応するけど、まぁそれはそれとして)
2)この窓をスライドさせて新しい行列を作る。
3)そして、このフィルタのパターンを色々用意しておいてそれぞれごとに行列を作る
4)フィルタが画素外に出てしまわないようにすると、その分行列がちいさいなるのでその領域は0などでパディングしておく。
・ここまでが「畳み込み層」とよばれるもので、この後が「プーリング層」とよばれているようだ。
5)こうしてできたものをたとえば縦横1/2に圧縮する。まぁ1/2なら縦横2つの画素の中の最大値をとるという方法が紹介されていたけど、「ぼかしている」という感じでもある。すると、縦横1ドットずれても結果は同じになる。
6)こうして出来上がったもの(縦横1/2の画像データ×フィルタ数)分のデータを全結合ニューラルネットで学習させる。
・そうすると、たとえば、横棒に強く反応した画素の右隣に縦棒に強く反応する画素があったとすればこれはそのあたりの場所で十字とかT型などの交差に反応するようなニューロンが生まれる可能性があるということになるのだろう。
・VOUTIONの字句を活かすなら、製糸工場など糸を紡ぐときのように、「窓」エリアから伸びた細い糸(画素データ)がまとめられていくようなのをイメージすると良いのかなという感じ。
・前処理はたぶんちょっとデータ数も多いけど「難しくはないけど手間はかかる」という類だろう。
・たぶん、フィルタ部分も初期値は適当に決めて学習するに従って最適化していくことになるのだと思うのだけど、この学習のやり方がCNNのツボなんだろうな。
2026.02.26 09:22
全結合2層がmnistで約95%。それなりに認識できた…かな?
・さて、MNISTでいろいろやってみている。先頭の1000個を学習させて同じデータで判定を見るとほぼ100%(正答数が1000個だったり999個だったり)となる。
・ならばということで次の1000個の判定をやらせたら87%程度に落ちてしまった。
・過学習なのかなとパラメータ類をいじってみたり、入力データをシャッフルして順番がバラバラになるようにしてみたけどあまり変わらない。
・ということは学習するパターンが少なすぎるのかなということで、6万個のデータのうち5万個を学習用に使って(1000個ずつ50回に分けて毎回シャッフルしてから学習)これを100回繰り返し学習。その後5000個目からの1000個でテストしたら正答率94.8%と出た。
・まぁ、いまどきmnistでの正答率は99.5%以上が当たり前な世界らしいから誤答率が1桁違うけど、何の工夫もない単純な2層のネットワークでもこのくらいまで追い込めるんだな。
・一般的にはどうなんだろうと思ったけどやった人は少なくてPyTorchを使った例などを見ていても3層にしていて、第1層が画素データ数あることにしているらしい。
・こちらは第1層が128個、出力層が10個ということを考えるとこんなもんか。
2026.02.25 16:24
MNIST面白いな
・ご近所イオンの三井銀行が混んでるなと思ったら今日は25日だったか。
・なんとなく「グノーシア」を見ているけど、なんとなく登場するキャラクタとその色付けだけ決めて、どういう話が作れるかという感じだな。まぁ、Re:ゼロに見られたようなループものの極限というところか。
・というところで、MNISTを扱ってみる
といっても、対して難しいことはなくて、28x28の784バイト分の入力があり、0から9に対応するワンホット出力(正解のところだけ1になる出力)が10個。間は適当で128個の[784,128,10]の2レイヤのニューラルネット。MNISTデータの読み込みはこれまたGCCに尋ねてこんな感じでいけるなというところ
def load_mnist_images(filename):
with open(filename, 'rb') as f:
# 最初の16バイト(ヘッダー情報)を飛ばす
data = np.fromfile(f, dtype=np.uint8, offset=16)
# 28x28の画像に成形し、0.0〜1.0に正規化
return data.reshape(-1, 784) / 255.0
def load_mnist_labels(filename):
with open(filename, 'rb') as f:
# 最初の8バイト(ヘッダー情報)を飛ばす
data = np.fromfile(f, dtype=np.uint8, offset=8)
return data
で、まぁ、こんな感じにすればXに学習データ、Tに答えが入る計算。
X_train = load_mnist_images('../mnist/train-images-idx3-ubyte')
Y_train = load_mnist_labels('../mnist/train-labels-idx1-ubyte')
X_train.reshape(-1,784)
X = np.array(X_train[:1000])
indices = np.array(Y_train[:1000])
size = 10
T = np.eye(size, dtype=int)[indices]
とりあえず6万個は多すぎるので、1000個くらいで試すことにしてどうなるかなとやってみたら、いきなりオーバーフロー連発。ウェイトの初期値にsqrt(2.0/size)を掛けると良いよとか、学習率は0.01くらいにしてみては?というアドバイスをGCCにいただきながらちょこまかと自分なりに調整していったら結構いい感じで収束しはじめた。
だいたい800回くらい回すとほぼ落ちついてきて、学習後の先頭100個の判定結果と教師データ(正解)はこんな感じ
出力結果:
[5 0 4 1 9 2 1 3 1 4 3 5 3 6 1 7 2 8 6 9 4 0 9 1 1 2 4 3 2 7 3 8 6 9 0 5 6 0 7 6 1 8 7 9 3 9 8 5 9 3 3 0 7 4 9 8 0 9 4 1 4 4 5 0 4 5 6 1 0 0 1 7 1 6 3 0 2 1 1 7 9 0 2 6 7 8 3 9 0 4 6 7 4 5 8 0 7 8 3 1]
教師データ:
[5 0 4 1 9 2 1 3 1 4 3 5 3 6 1 7 2 8 6 9 4 0 9 1 1 2 4 3 2 7 3 8 6 9 0 5 6 0 7 6 1 8 7 9 3 9 8 5 9 3 3 0 7 4 9 8 0 9 4 1 4 4 6 0 4 5 6 1 0 0 1 7 1 6 3 0 2 1 1 7 9 0 2 6 7 8 3 9 0 4 6 7 4 6 8 0 7 8 3 1]
・2層にしただけでこんなにうまく行くものなのか。なんだか面白いな。
・もう少しMNISTで遊んでみるか。
2026.02.24 15:40
MNISTの準備
・朝からちょっと頭痛がして全身がだるい。
・とりあえず気力でMNISTの手書き画像認識の下調べ。
・結局、あまりたいしたことはなかった。要するに画像データとそのデータの答え(ラベル:0〜9の数値)のファイルがあって、画像データの先頭16バイトとラベルの先頭8バイトがヘッダ。
・で、その後は画像データが28x28(1画素が1バイトの濃淡データ)、ラベルは1バイトで0〜9の値を示しているだけ。
・で、学習用のデータが6万セット、本番用のデータが1万セット用意されている。
・もちろん、使い方は自由なので、学習用のデータの先頭1000個で学習して次の1000個を学習結果の評価用としても良いわけだ。
train-images-idx3-ubyte.gz(6万セットの画像)
train-labels-idx1-ubyte.gz(6万セットのラベル)
t10k-images-idx3-ubyte.gz(1万セットの画像)
t10k-labels-idx1-ubyte.gz(1万セットのラベル)
2026.02.23 06:57
画像認識に発展させてみようか
・さて、せっかく作ったのでもうちょっと遊ぶ。
・簡単な画像認識というのか、手書き文字認識くらいはできるんだろうか。
・今のプログラムではたとえば[4,8,3]というリストを与えればとやれば4入力3出力で入力層が8個、出力層が3個のネットワーク、[4-8-5-3]なら、入力と出力の間にニューロン5個の隠れ層が1層構築されるという具合で結構いろいろな形を作って遊べる。
・ということで、出力をワンホット化して、3x3の画像の分類をさせてみる。まぁ、とりあえず4-8-2で、"|"と"ー"のパターンという単純なもの。正解は"[0,1]"と"[1,0]"でやってみると100回もしないうちに収束。
・それならば・・・とちょっと意地悪して実数の乱数で3x3のパターンを3つ作ってこれを同じように分類。更に6個、12個と作ってこれを3分類させてみたけど、割と良い感じで収束する。
・つまり、これって人間の目にはランダムパターンにしか見えないけど、ニューラルネットは数字として認識できているということだな。なんとなく暗号みたいに使えそうだな。
・超有名なMNISTだと28x28で、784点あるのか。訓練用データ6万個を一気に始末するのはさすがに大変かと思ったけど784×60,000=47,040,000。まぁ44M程度という感じか。1データ4バイト実数にして176Mbytes。メモリ量的には思ったほど大したことないけど、これを行列演算に使うとなったらやはり大変だろうしな。まぁ100個なり1000個なりごとに分割して学習させる感じかな。
2026.02.22 07:51
XOR対応であれこれお試し
・XORは実はそこそこ厳しいものらしいので、しばらくこれで遊んで見ることに。
・LayerStruc=[2,8,4,1]みたいな感じでニューロンのレイヤ構成を自由に作れるように書き換えて、レイヤ構成を変えてみたり、初期値を変えてみたりして試してみている。
・とりあえず2-4-4構成でウェイトを-0.5〜+0.5の一様乱数、バイアスの初期値を0.2程度にして活性化関数をLeaky ReLUにしてみたらこんな感じでサクッと落ち着くことが多くなった。
・一般的には0を中心に正規分布させたほうが良い結果が得られやすいようだけど、XORに関してはそうもいかないのかな?
2026.02.21 13:30
2層でXORができた
・さて、なんとなく1層を任意の入力点数、任意のニューロン数で作ることができるようになったので、2層…2段カスケード接続したらどう?というのをやってみる。
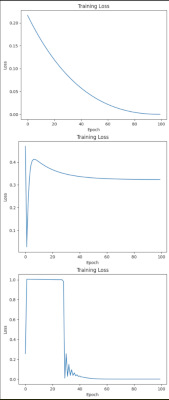
1層目が2入力のニューロン4個、2層目が4入力のニューロン4個。で教師データは同じものを与えて同時に教育してみる。ウエイトやバイアスの初期値は乱数なので、4回分同時にチェックする格好。
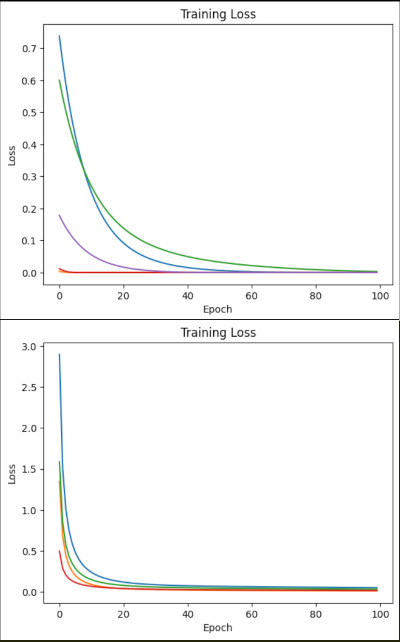
で、最終段の偏差の自乗がどうなるのかを見てみたのがこのグラフ。上が1層にしたとき。圧倒的な収束の速さだな。
・調子に乗ってXORをやらせてみたら収束したりしなかったり…さて、何が悪いのかな。
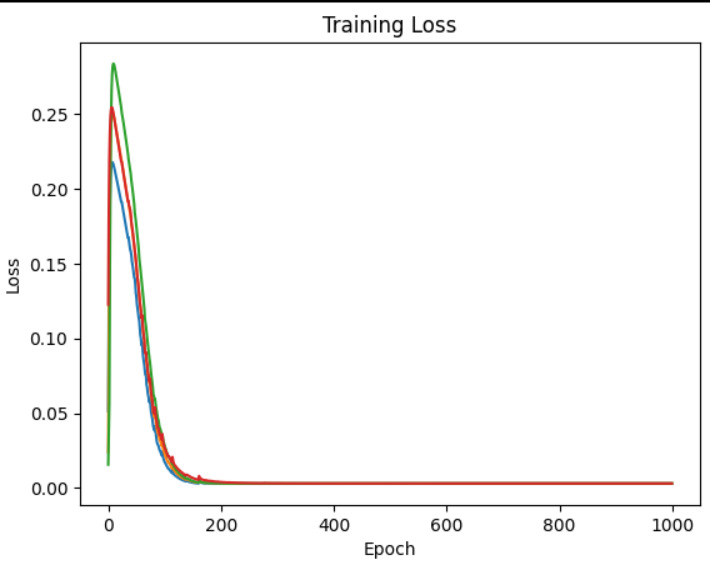
・というところでGCCへのお問い合わせなどもしていろいろいじっていたらXORでも収束するようになってきた。乱数をstandard_normal、つまり0を中心にした正規分布乱数にして、Learning Rateもちょっといじったり。更に1層目のニューロン数を8個に増量。これが一番効いたようだ。XORを教師データとして入力して誤差(前回のは偏差の自乗をグラフにしたけど、これは符号付き)の変化を撮ってみたらこんな感じ。繰り返しやってみるとだいたい500回くらいで収束する。実務的にはこの収束した状態を見て学習済みとして推論用のパラメータにすれば良いんだろうな。
・この学習過程で時々発振というのかリンギングを起こしたような波形が出てくるのが面白いところ。フィードバックがかかっていて、位相が180度反転してループゲインが1未満ならこういう減衰振動になる。
・電子回路ならここでダンピング抵抗を入れたりフェライトビーズを入れたりする感じかな。
・GCCにお尋ねしていたら、AIの世界でもこうした現象を抑制するフィルタみたいな式を入れ込むことが実際に行われることがあるらしい。いろいろつながってるな。
2026.02.20 22:59
ぼちぼちと
・20日ということで、ちょっと現金をおろして記帳。ついでにキャッシュレス関係にチャージもしておく。
・ということで書いたついでにバックプロパゲーションの処理部分を独立させて、多層化しやすそうな構造に書き換えておく。
・なんとなく頭の中もプログラムも整理されてきたな。
・太田光が首相に対して「消費税減税ができなかったらどうするのか」と訪ねたら「意地悪な質問ですね」と答えたとかいうことをラジオで取り上げていた。
・「普通な質問なのに・・」と言ったあとに沖縄の知事が地元の案件について同じような質問を受けたときに「できなければ腹を切る」と言ったとかいうことを持ち上げて「覚悟が聞きたかった]などと言っていた。
・絶対うそだろう。この質問は「言質を取ろう」という悪意ある質問であろう。それは、この質問がどのような答えを期待しているのかを考えればすぐわかることだ。「できないかもしれない]といえば無責任だと非難し、「できなければ辞職だ]と「覚悟」とやらを語れば後日成立が遅れたり先送りになったときに「辞職だと言ったくせに」といって非難する。そのための材料をを得ようとしているのだろうとしか考えようがない。
・「違う。単に覚悟の程を聞きたかっただけだ」というなら「後日これをネタに非難することがないと言い切れるのか。もし非難するような言動をしたらどう責任を取るのか」と尋ねればきっと、「首相という立場とは重さが違う」とか「ジャーナリズムは・・・」とか言って逃げるのだろうな。
2026.02.19 22:27
バックプロパゲーションでフィードバックする値は
・だいぶ形になったので、多層化を考えていくことにする。
・となると、今までニューロンクラスの中でやっていた教師データとの比較は外に出すことになるわけか。
・ところで、今のプログラムだと入力のデータパターンについて同時演算させている。今は2入力ANDを扱っているので、[00][01][10][11]のそれぞれごとに初期値の違うN個のニューロンがどういう値を出力するのかを4行N列の行列で得ているという具合。
・ここからバックプロパゲーションで戻す値はというと、セルごとの入力点数(この場合なら2)にセルの数を掛けた分の入力端子があるようなイメージになって、それをそれぞれのニューロンが持っているバックプロパゲーションでフィードバックする値をウェイト値で按分したもの・・・だから2N行1列の行列を得るのか?いや、でもそれはなんかおかしいのではないか。
・と、考えていてなんのことはないと気付く。それぞれのニューロンの入力端子をA,Bとしたとき、全部のニューロンの入力端子A同士、B同士がつながったよう状態になっているので、フィードバックする値は全部のニューロンのフィードバック値を足したものになるはず。ってことは普通に行列演算でいける。
2026.02.18 19:27
セルを4つにしてみる
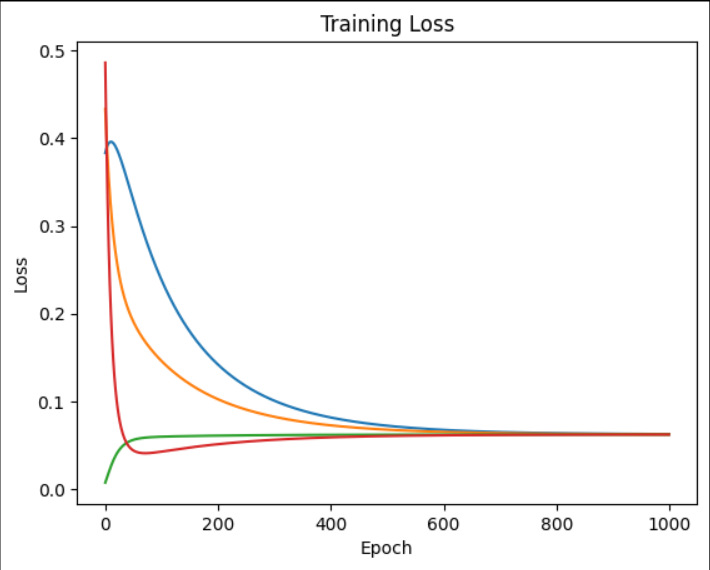
・間違っていたところがわかった。うっかりnp.sum()を残していたために2個の入力に同じ値がフィードバックされてしまっていた。
・修正してみたら良い感じ。ついでなので、セルを4つに増やして改めて学習の進み方を見た。4つのセルの学習の進み方を見ると面白いように同じところにおちついていく。
・そういうものかな。
2026.02.17 11:36
ニューロン1個で少し遊ぶ
・とりあえず2入力のニューロン2個を並列配置して行列使って同時進行させてみる。
・要は[[0,0],[0,1],[10],[11]]の二次元行列を入力、[[0,0],[0,0],[0,0],[1,1]]を正解データ(実際には[[0],[0],[0],[1]]をブロードキャストで拡張するけど)として、出力として[[0,0],[0,0],[0,0],[1,1]]が得られるかどうかというところ。
・実際には浮動小数点データで得られるのだけど。なぜイマイチ収束しないんだろうと思いながら、コードの間にprint(f"...")なのを挟んでいく。printf()ではなくprint(fというあたりにちょっと感じるものも。
・見にくいのでnp.where(x>0.5,1,0)を使って1/0に変換したらそれなりになった。なんとなく目がくらんでいただけで、結構それなりだったのか。
・学習の回数と教師データとの誤差をグラフかすることにして、初期値やら学習率(LR)やら活性化関数(Leaky ReLUにしてみたけど)にちょっと細工をしてみたりするといろいろ面白い。
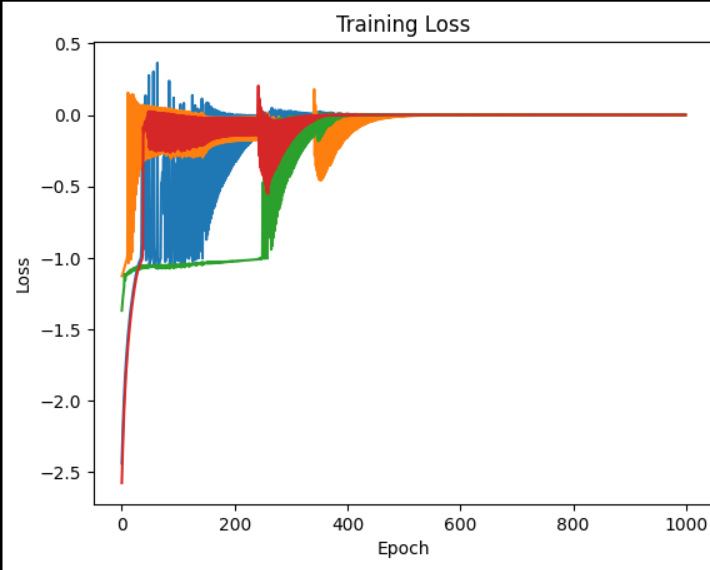
・学習を0.001からドンドン・・と増やしてみたのがこれ。
で、まぁこれは一例でやるたびにグラフの形状は大きく変わる(初期値を乱数にしているからでもあるけど)けど、大まかにはLRを大きくすると学習は早く進むようだけど、暴れやすくなる。オーバーシュートやアンダーシュート、リンギング波形みたいなものも出てきたりして、なんとなくハード屋さんの世界とも通じるものを感じたり。
・だとすると、バックプロパゲーションにLPFなんか入れて「誤差が大きく変わったら少し抑える」とかすると暴れにくくなるのかな?
・・・・・
・2/18追記:と思ったのだけどプログラムでなんか変なところがあった。リトライだな。
2026.02.16 17:57
行列演算やらnp.sum()やら・・・と
・車があまりにも汚くなってきた。灯油とガソリンの補充をしたとき、洗車機があいていたのと、気温もちょっと高めで寒くなかったので洗車することに。今夜雨か雪という予報もでているけども。
・ここは最初にメニューを選ぶのではなく、最初に支払い方法の選択なんだな。拭き上げ用のタオルの置き場とかも悩んでしまったり。
・というところで、帰ってきてから振り込みもしておく。
・毎度のことながら社会保険料は高いな。まぁ3月に入ったら給与減額して社会保険料もガクッと落とせる予定だけど。
・そんなところで、昨日の続きである。
・普通にスカラーなら、入力X1、X2にウェイトW1,W2を掛けてバイアス値を足すのだから、普通なら(X1*W1+X2*W2+B)というだけで良いのだけど、ここで、配列だからXは[[0,0],[0,1],[1,0],[1,1]]という二次元配列で、ウェイトWは[[W1],[W2]]という二次元風味な2行1列の配列で
np.dot()を使って掛け算してやれば、縦方向に答えが並ぶ。
・というのは数学の行列式ではイメージできるけど、こんなふうにプログラミング言語で[]が並ぶとつい混乱しそうになる。慣れの問題なんだろうけどな。
・こうやって得られたものからバックプロパゲーションをするとき、左から(1,1,1,1)を掛けるのも面倒そうだなと思ってGCCにお尋ねしたら、np.sum()が使えるし、速いよと教えてくれた。
・さて、とりあえず実行してエラーにはならなくなったけどうまく収束しない。たぶんどこかで凡ミスしているのだろうな。
2026.02.15 17:40
2層化は行列演算で考えよう
・とりあえず積和+活性化関数のニューロン1個だけ動いたのだけど、これではORが実現できない。これが1960年代にパーセプトロン・・・1層(入力層と出力層のみ)のニューラルネットだと駄目だということで、第一次のAIブームを終焉に追い込んだという。
・現在から過去に向かって「天の声」を下ろすなら、1個のニューロンでNORは実現できるし、NORを組み合わせればXORは実現できるんだから…ということになるけど、当時はここで行き詰まったらしい。
・ということで、こちらも多層化してXORを解いてみよういうところだけど、その前にまとめて行列演算で片付けることを考えてみる。
・以前はとにかく先に進みたくてニューロンのオブジェクトを一つずつ並べてループで回して処理してみたのだけど、コードがやたらと多くなってうっとおしくて仕方なかった。やはり複数の入力を行列で処理するほうがずっと美的だろう。
・たとえば2入力のセルを2個をまとめたものを1つのオブジェクトにして2つのオブジェクトに4パターン([0,0][0,1][1,0][1,1])を入れた時の答え(合計8個)を一回の行列演算で得てみようということ。数学的な式としては簡単だけど、プログラムはなにせ1次元的な文字列の並びなので書き方にちょっと気を使う。
・もちろん、教師データセットが膨大になるとメモリも食いそうだけど、今はとりあえず2入力でXORが解けるかということだしな。
2026.02.14 23:34
ニューロン1層目
・ニューロンの基本がそれぞれの入力に重みパラメータを書けて足し算し、更にバイアスを足し込んで活性化関数で非線型性を与えるということか。
・GCC(Gemini/ChatGPT/Copilot)はシグモイド関数を使った例を示してきたけど、ReLUが主役じゃないの?ということで書き換えてみる。
・積和部分の出力をzとして出力yは
y=z if (z>=0) else 0.01*z
オリジナルのReLUだと負の領域で微分値が0になるけど、ニューロンが死んで出力が0に固着する可能性があるかな?ということで、ちょっとだけ残すようにしてみる。これをLeaky ReLUと呼ぶらしいことをGCCに教えてもらった。
・ちょっと調べるとNumpyにも三項演算子的なものはあって
y=np.where(z>0,z,0)
とか書けて、こいつは行列でも一発でやってくれるというスグレモノなので、
z=np.array([-2,-1,0,1,2])で
y=np.where(z>0,z,0)
なんて書くとyがarray([0,0,1,2])になると知った。
・np.whereは第一引数がarray型なら良いので
z=[-2,-1,0,1,2]
y=np.where(np.array(z)>0,z,0)
なんてやっても、zをarray型に勝手に変換してくれるのか。なるほど。
2026.02.13 20:21
Pythonの型チェック
・というところで、忘れた頃に再チャレンジのニューラルネットワーク。
・まずはここからでしょということで、再びニューロンをPythonで。しかし、改めて思う。Pythonって雑というのか、おおらかというのか。
・わかって使っている分には便利ではあるけれど、逆におおらかすぎて、型を間違って与えると痛い目にあう。
・たとえば、
x=[1,2,3]
y=np.array(x)
で、
x*2は[1,2,3,1,2,3]
y*2はarray([2,4,6])
になるという具合。個人でボソボソやる分にはいいけど、大規模開発なら盛大なバグの養殖場になってしまいそうだ。
・ということで、例によってGCC(Gemini/ChatGPT/Copilot)に頼ってみたら、
from beartype import beartype
とやって(baretypeかと思ったら本当に熊のbear)、関数の直前に
@beartype
xxx_func(x:int, y:np.ndarray)->float:
みたいに型を指定してやると、チェックしてもらえるらしい。また、
from beartype.claw import beartype_this_package # 「爪 (claw)」という強力な機能
beartype_this_package() # これをプログラムの最初に1行書くだけ
と、プログラムの先頭に書いておけば自動的に全関数が対象になるらしい。
・更に関数を引数にとった場合、
from collections.abc import Callable(abcはAbstruct Base Classes)
としたあと、
def executioner(func: Callable[[int, int], int]):
のようにすると、引数にした関数(ここではfunc())の引数や戻り値の型や数がチェックされるという仕掛けらしい。
・実際にどうなのかなと色々いじって遊んだあと、ざっと書いていたニューロンの動作が変になったので、調べていったら単なるスカラーのはずなのに行列が渡されているけど、エラーにもならずにそのまま突っ走っているのが確認できた。早速覚えたてのこれらを埋め込んで見たら見事に引っかかった。
・エラーメッセージが著しくわかりにくいけど、じっと読んで該当する行を見つけてじっと眺めていたら、「あっ!」な記述が見つかった。
・これを修正して改めて実行したら予定通りの結果が得られた。
2026.02.12 16:14
金利の時代
・少し暖かくなってきたな。イオンに行って記帳を済ませておく。しかし本当に金利がつく時代になったんだな。
・円が急騰ということらしいけど、まぁこれから先はもう少し円高に振れるのだろう。
・円安になると外貨預金は金利分も上がるわけで、円高のときに外貨預金した人は大喜びなのだろうな。私もほんの少しだけ・・・ガストで数回ランチできるかどうかという程度だけドルを持っているけど(そうすると他の手数料が格安になるので)、今ならドリンクバーくらいは付けられるかなという感じ。
・ただ、当然のようにRaspberryPiやらArduinoやらの値段も上がってしまうわけで、そのあたりはなんともなぁと思ったり。
・こういうときはやはり手持ちの在庫を引っ張り出さねばなというわけでもないけど、ちょっと探しものをしてあちこち引き出しを開けていたら、出てくる出てくる評価ボード。
・この際もう一回いろいろ頑張ってみるか。
2026.02.11 07:32
Pythonちょいちょい
・ぼちぼち確定申告でもしておかねばと思って通帳を眺めたら最近記帳していなかった。最近は土日祝日も記帳できたりするけど、今日は思い切り寒いし、明日にしよう。
・さて、ではというところで少しPythonのNumpy関係を少しいじりつつ、ノートにメモをとりつつというところ。今までちょっと曖昧になっていたところがスッキリしつつある感。
・しかし、Gemini+ChatGPT+Copilot(最近の使用頻度順):ジェチャコは便利で、「こう書けない?」とか「これだと駄目そうだね」とかやるとせっせと説明してくれる。もちろん、ある程度裏取りは必要ではあるけど。
・言語関係は割と良いけど、ツール関係の使い方についてはどうも同じ情報を元にしているのか、GeminiとChatGPTが同じ間違いをしてきたりするし、ライブラリ関係は古い情報のままコード生成してきて、色々やっているうちに「それは既にLegacyだから・・・」なんて言い出したりする。いや、お前が書いたコードでそれ使ってるだろと突っ込みたくもなるけど。
2026.02.10 07:59
pyqt5が必要か
・さて、ぼちぼちとやるべく、numpyとmatplotを入れて昔作ったプログラムでグラフ描画させようとしたら表示されない。
・ちょっと検索したらPyQt5を追加すれば良いらい。ということで
pip install pyqt5
・これで改めて試したら無事動作。
ーーーーー
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return (1/(1+np.exp(-x)))
def relu(x):
return (np.maximum(0,x))
x = np.arange(-5.0,5.0,0.1)
#y = sigmoid(x)
y = relu(x)
plt.plot(x,y)
#plt.ylim(-0.1,1.1)
plt.show()
ーーーーー
2026.02.09 12:48
久々Python
・昨日雪がそれなりだったけど、珍しくフカフカな雪でどんどん溶けていく。こういうのをパウダースノーっていうのかな?
・久しぶりにPythonを使うか・・・と思ってちょっとリハビリモードで以前書いたものを動かそうとしたら、numpyが無いよと言われた。
・そうかそうか・・・とpip install numpyしたらなんか叱られた。
・よくわからなくて検索したら、仮想環境で動かすんだということ。言語処理系レベルで仮想環境とは一体なに?ということろで例によってお尋ねしてわかった。
・今までの一般的な言語処理系だと、インストールしたライブラリ類の種類やバージョン、パス設定などの組み合わせによって同じプログラムがちゃんと動かなかったり挙動が変わったりということが起きてしまう。
・そこで、デフォルト状態から変更・追加などをされたものをユーザが指定したディレクトリの下に格納しておいて、切り替えて使えば良いじゃないかという発想か。
・たとえば
A)数値演算したい
B)組み込みのAIを試してみたい
C)USB接続したい
D)デバイスから取り込んだグラフを描画したい
などというものがあったとき、今まではこれらに必要なライブラリ類を全部インストールした一つの開発環境になってしまっていた。
一体今回のものでは何が必要なのかわかりにくいし、 他の人が同じ環境を別に作ろうとしても難しい。
・ということで、
A)のための環境(使っているライブラリ類などの動作環境)
B)のための環境
・・・
という感じでそれぞれのフォルダにまとめて使いたい環境に切り替えて使う。pip installとかすると今使っている環境用のフォルダにインストールされるという具合。
適当なディレクトリで
python3 -m venv .venv_A
とかすると、.env_Aというディレクトリが作られて、この下に最低限必要なものが書き込まれる。pythonの環境もインストール直後のような状態になる
(ちなみに、デフォルトのシェルの状態はクリーンではなく、Linux側で必要なものがあれこれ入っているけど、activateすると、これらも全部外された、本当にクリーンな状態になる)
ここで
source .venv_A/bin/activate
とかすれば、パス設定なども含めて.venv_Aな環境に切り替わる。で、
pip install numpy
とかすると、グローバルな言語処理系。環境ではなく、.venv_Aディレクトリの下にインストールされる。
これであれこれやった後に
deactivate
とすれば、activateでセットされたパスだのなんだのは綺麗さっぱり忘れて元に戻る。もちろん、これとは別に
python3 -m venv .venv_B
source .venv_B/bin/activate
すれば、.venv_B用のクリーンな環境になる。
・で、Aの環境を引き継ぎたいとか言うことももちろんあるし、配布するときに「これが必要だよ」というのも教える必要がある。
このときは、.venv_Aをactivateして使っている状態で、
pip freeze >setup_env.txt
とかやって、deactivateして.venv_Bをactivateして環境を切り替え。そして
pip install -r setup_env.txt
なんてやれば必要なものがインストールされて環境が再現される。
・なるほどね。というところで、更にGeminiしたら「VSCodeにMicrosoftのPythonなエクステンションとJupyter Notebook Renderersを入れると良いよってことで、入れてみる。
面白いのはソースコードの中に
#%%
というのを入れると、ここがプログラムの切れ目(セクション)ということになってくる。たとえば、
#%%
import numpy as np
import matplotlib.pyplot as plt
# データを生成 (0から10までを100分割)
x = np.linspace(0, 10, 100)
y = np.sin(x)
print(x,y)
# グラフの設定
#%%
plt.plot(x, y, label='Sine Wave')
plt.title(loc="center", label="Hello Virtual Environment!")
plt.xlabel("x-axis")
plt.ylabel("y-axis")
plt.legend()
# グラフを画像として保存
#%%
plt.savefig("my_plot.png")
print("グラフを 'my_plot.png' として保存しました!")
# %%
てな具合にしてやると、#%%の上に「セルの実行」とか「以下を実行」とか出てくるので、ここをクリックすると次の#%%まで実行してくれる。
・これで実行結果(たとえばグラフ表示)がイマイチだなと思ったら、今実行したセルのコードを変更してもう一回描画のところのセルだけ実行するなんてことができる。最初から全部やりなおし・・・ではないので便利ということ。
・ということでやっと時代に少し追いつけた感じ。
2026.02.08 12:13
Mbed/MbedOS終了カウントダウン通知
・そういえば先日ARMさんから改めてメールが来ていたけど、Mbed Platform End of Life in July 2026。Mbed OSもまた同時に終了。
・だいぶ前からアナウンスはされていたから、期限迫っているよというお知らせなのだろう。改めてMbed.comに置いているものは吸い上げておいてねといっている。
・MbedOSはGitHubの方に残されてるけど、使う人は要るのだろうかな。FreeRTOSとかそっちに走るんじゃないだろうか。
・簡単なスケジューラは昔作って重宝してたなぁ。シングルステップ機能を使って実行トレースしたりして。
2026.02.07 22:34
RaspberryPiZero2WのAP化(2/8追記)
・雪が振りそうとかいうお天気で、外出を中止してちょっと時間ができたので、キーボードの上に敷く布の作成
・といっても、四角く切って端を折ってミシンがけするだけなので簡単。以前買っていた生地もでてきたので2つ作って1時間もかからなかった。
・というところで、以前買った3Dプリンタを外部につながらないLAN・・・ローカルエリアなネットワークだけで使おうということでルーターを考えていたのだけど、考えたらRaspberryPi Zero2Wもアクセスポイント化できるだろう。
・ということで、Geminiに聞きながらあれこれ設定をいじっていたらできた。スマホやPCからSSIDを指定して接続し、自分で決めたパスワードを入れるとちゃんと接続された。
・これで、
Bambu Studio用のLinux仮想マシンを作る
USB-WiFiドングルをPCに取り付け
USB-WiFiだけをBambu Studio仮想マシンに接続する
とやれば、あとはスッキリいける・・・はずだし、BambuStudioが勝手に外に出ていくこともできない・・・はず。
ーーー
2/8追記:
ということで、設定方法のメモを残しておこう。RaspberryPiのIPアドレスは、192.168.50.1で、DHCPで192.168.50.100-200を割り当てることを想定
これでうまく動けばRaspberryPiのAPに接続して
ssh (user名)@192.168.50.1
とかやってユーザのパスワードを入れてsshで遊ぶこともできる
LANアダプタを追加してルータ化する手もあるけども、それはまた後日としよう。
・必要なもの
sudo apt install hostapd
sudo apt install dnsmasq
あとsystemd-networkdも要るけど、既に入ってる?(失念)
sudo systemctl enable sshもついでにやっておく
・/etc/hostapd/hostapd.confを作成。中身は
interface=wlan0
ssid=(SSIDの文字列)
hw_mode=g
channel=6
ieee80211n=1
wmm_enabled=0
auth_algs=1
wpa=2
wpa_passphrase=(パスワード文字列)
wpa_key_mgmt=WPA-PSK
rsn_pairwise=CCMP
ctrl_interface=/var/run/hostapd
ctrl_interface_group=0
・/etc/default/hostapdに追記
DAEMON_CONF="/etc/hostapd/hostapd.conf"
・/etc/systemd/network/10-wlan0.networkを作成(固定IPで作成)。中身は
[Match]
Name=wlan0
[Network]
Address=192.168.50.1/24
ConfigureWithoutCarrier=yes
systemd-networkdの有効化
sudo systemctl enable systemd-networkd
sudo systemctl start systemd-networkd
(動作確認)
systemctl status systemd-networkd
active(runningならOK)
・/etc/dnsmasq.confの後ろに追記
interface=wlan0
dhcp-range=192.168.50.100,192.168.50.200,255.255.255.0,24h
(孤立LANなので下記は無意味だけど入れておいても良い)
domain-needed (ドメイン名の無い名前をDNSに問い合わせしない)
bogus-priv (ローカルのIP逆引き問い合わせをしない)
・hostapdとdnsmasqを起動
sudo systemctl unmask hostapd
sudo systemctl enable hostapd dnsmasq
sudo systemctl restart hostapd dnsmasq
・特定のデバイスに固定IPを割り振りたい時は
/etc/dnsmasq.confに下記のような具合に追記する(最後につけるのはデバイスの名称:省略可能だけど、つけるとping SmartPhoneみたいに名前が使える)
dhcp-host=aa:bb:cc:dd:ee:ff,192.168.50.10,SmartPhone
(DHCPの払い出し範囲を避けること)
書き換えたら
sudo systemctl restart dnsmasq
でdnsmasqの再起動も忘れずに
・動作状態確認コマンド集
・AP(アクセスポイント)が動いているか(hostapd)
systemctl status hostapd
=>Active: active (running)
になっていればOK
・APのインターフェースの状態
iw dev
=>Interface wlan0
type AP
ならOK
・hostapdログ
journalctl -u hostapd -e
=>wlan0: AP-ENABLED
ならOK
・DHCP(dnsmasq)が動いているか
systemctl status dnsmasq
・DHCP払い出しログ
journalctl -u dnsmasq -e
=> DHCPDISCOVER(wlan0)
DHCPOFFER(wlan0)
DHCPREQUEST(wlan0)
DHCPACK(wlan0)
・RaspberryPi自身のIP
ip addr show wlan0
hostname ーI でも良い
・接続している端末一覧
arp -a
ip neigh でも良い
・接続中のクライアントの情報(WiFiレベル)
iw dev wlan0 station dump
・まとめて確認
systemctl --no-pager status hostapd dnsmasq
ip addr show wlan0
iw dev wlan0 station dump
2026.02.06 08:08
キーボードの上に敷く布
・さて、そんなところでキーボードの上に敷いている布がだいぶ汚れてきた。以前コーヒーをこぼして痛い目にあってから薄い布を敷いて使っている(どうせ見てないし)。といっても、100均で買った布の端をミシンでかがっただけのものだけど一枚しかなくて洗い替えがないのでずっと使っていたらだいぶくすんできた感じ。
・ということで、改めて100均へ。30cmX25cmというのがあった。なんだか昭和なセンスの柄だけど大きさがちょうど良さそうだなと思って買ってきたらなんか大きい正方形。実は30cmX30cmだったというオチ。
・やはりちょっと大きすぎるな。ちょっと時間を見てサイズ合わせて端もちゃんと始末しておこう。
2026.02.05 18:15
Tnx.Gemini
・気がつくとsudo apt installでエラーが出てしまうという現象で困っていたのだけど、エラーメッセージを見てもよくわからないのでダメ元でGeminiに投げてみた。
***
install-info (7.1-3build2) を設定しています ...
/usr/sbin/update-info-dir: 2: /etc/environment: SALT_LICENSE_SERVER:
not found
dpkg: パッケージ install-info の処理中にエラーが発生しました (--configure):
installed install-info package post-installation script subprocess returned err or exit status 127
処理中にエラーが発生しました:
install-info
E: Sub-process /usr/bin/dpkg returned an error code (1)
***
・Geminiの回答は
結論から言うと、/etc/environment という設定ファイルの内容が壊れている(書き方を間違えている)ことが原因です。
ということだった。じゃあ、/etc/environmentは?ということで開いたら
***
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin"
SALT_LICENSE_SERVER = "/home/(中略)/Download/Altera_Intel/Questa/LR-278536_License.dat"
***
となっている。これをそのまま投げたら瞬間回答。
原因がはっきりしました!/etc/environment の書き方が、ほんの少しだけルールから外れています。
このファイルはシェルスクリプトではなく「単純な変数割り当て」のみを受け付けるため、=(イコール)の前後にスペー
スを入れてはいけません。
修正内容
現在の状態: SALT_LICENSE_SERVER = "/home/..."(スペースがある)
修正後の状態: SALT_LICENSE_SERVER="/home/..."(スペースを消す)
ということ。そういうことか。スペースを消去して
sudo dpkg --configure -a
すれば良いよということだったので、やってみたら無事apt installできるようになってきた。
珍しくちゃんと役に立ったな。
2026.02.04 22:26
ドキュメントできた&投票
・昨日の続き。
・なんか格好良くないけどとりあえずドキュメントもできたので、プログラム類をまとめてアーカイブ。
・ちょっとサイズが大きいなぁということで、GoogleDrive経由でお渡しすることにした。まぁ良いだろう。
・なんとなく一息ついた感もあって、期日前投票に行く。昔は開票速報がなかなか面白かったけど、近年は当確があまりにも早く出すぎて面白くないけどもね。
・イオンが会場というのはなかなか利便性高い。今回は本当に選択肢がなくて消去法でまぁここかというところ。
2026.02.02 21:51
RaspberryPiへのドライバ組み込み&無事動作
・最終的なシステムではPCではなくRaspberryPiで動かすことになるので、PC上で作っていたプログラムの移植をする。
・といっても、アプリ自体はどちらもLinux上、そしてコマンドラインで動かすだけなのででもあるので、さほど大きな心配はしなくて良いだろう。
・ということで、とりあえずD2xxドライバのインストール。確かインストーラなんて使わないでコピーしただけだったよなと記憶をたどってPC側で/usr/local/libを見たらあったあった。libftd2xxなんちゃらのファイルが2つ転がっている。これだな
・とりあえず、ご本家サイトからARMV8用のファイルを落として展開して、こいつらをコピー・・・と思ってさぁどうしよう。RaspberryPi側でブラウザもインストールはされているし改めてダウンロードするのも良いけど、なにせZ ero・・・メモリ足りるのかな。
・ということで、そちらの道はやめてPC上でSDカードに書き込むことに。
sudo dd if=/dev/sdb of=./xxx.img bs=4M status=progress
でイメージファイルを作って
sudo losetup -Pf --show xxx.img
でループデバイスにしておいて
sudo mount /dev/loopxx ~/mnt
としてマウントしておけばよし。
・これでひととおり作業して出来上がったSDカードをRaspberryPiに差し込んで起動して、プログラムを再コンパイルしたら何事もなく動いた。まぁ、予定通りではあるけれどちょっと一安心。
2026.02.01 00:29
FPGAは一応の完成かな
・気がつけば2月か。
・ぼちぼちとソースコードの整理。大した長さではないのだけどタイミングが絡む部分だけにどうもややこしいのと、テスト環境がブレッドボードでにデュポンワイヤーで接続ということによる不安定さもあるようでなかなか。
・とりあえずはできたかな。あとドキュメントを書いたり余計な部分を削ったりという感じだろうけど。
・明日はRaspberryPi側をちょっと小細工だな。
- 1