2026.02.26 09:22
全結合2層がmnistで約95%。それなりに認識できた…かな?
・さて、MNISTでいろいろやってみている。先頭の1000個を学習させて同じデータで判定を見るとほぼ100%(正答数が1000個だったり999個だったり)となる。
・ならばということで次の1000個の判定をやらせたら87%程度に落ちてしまった。
・過学習なのかなとパラメータ類をいじってみたり、入力データをシャッフルして順番がバラバラになるようにしてみたけどあまり変わらない。
・ということは学習するパターンが少なすぎるのかなということで、6万個のデータのうち5万個を学習用に使って(1000個ずつ50回に分けて毎回シャッフルしてから学習)これを100回繰り返し学習。その後5000個目からの1000個でテストしたら正答率94.8%と出た。
・まぁ、いまどきmnistでの正答率は99.5%以上が当たり前な世界らしいから誤答率が1桁違うけど、何の工夫もない単純な2層のネットワークでもこのくらいまで追い込めるんだな。
・一般的にはどうなんだろうと思ったけどやった人は少なくてPyTorchを使った例などを見ていても3層にしていて、第1層が画素データ数あることにしているらしい。
・こちらは第1層が128個、出力層が10個ということを考えるとこんなもんか。
2026.02.25 16:24
MNIST面白いな
・ご近所イオンの三井銀行が混んでるなと思ったら今日は25日だったか。
・なんとなく「グノーシア」を見ているけど、なんとなく登場するキャラクタとその色付けだけ決めて、どういう話が作れるかという感じだな。まぁ、Re:ゼロに見られたようなループものの極限というところか。
・というところで、MNISTを扱ってみる
といっても、対して難しいことはなくて、28x28の784バイト分の入力があり、0から9に対応するワンホット出力(正解のところだけ1になる出力)が10個。間は適当で128個の[784,128,10]の2レイヤのニューラルネット。MNISTデータの読み込みはこれまたGCCに尋ねてこんな感じでいけるなというところ
def load_mnist_images(filename):
with open(filename, 'rb') as f:
# 最初の16バイト(ヘッダー情報)を飛ばす
data = np.fromfile(f, dtype=np.uint8, offset=16)
# 28x28の画像に成形し、0.0〜1.0に正規化
return data.reshape(-1, 784) / 255.0
def load_mnist_labels(filename):
with open(filename, 'rb') as f:
# 最初の8バイト(ヘッダー情報)を飛ばす
data = np.fromfile(f, dtype=np.uint8, offset=8)
return data
で、まぁ、こんな感じにすればXに学習データ、Tに答えが入る計算。
X_train = load_mnist_images('../mnist/train-images-idx3-ubyte')
Y_train = load_mnist_labels('../mnist/train-labels-idx1-ubyte')
X_train.reshape(-1,784)
X = np.array(X_train[:1000])
indices = np.array(Y_train[:1000])
size = 10
T = np.eye(size, dtype=int)[indices]
とりあえず6万個は多すぎるので、1000個くらいで試すことにしてどうなるかなとやってみたら、いきなりオーバーフロー連発。ウェイトの初期値にsqrt(2.0/size)を掛けると良いよとか、学習率は0.01くらいにしてみては?というアドバイスをGCCにいただきながらちょこまかと自分なりに調整していったら結構いい感じで収束しはじめた。
だいたい800回くらい回すとほぼ落ちついてきて、学習後の先頭100個の判定結果と教師データ(正解)はこんな感じ
出力結果:
[5 0 4 1 9 2 1 3 1 4 3 5 3 6 1 7 2 8 6 9 4 0 9 1 1 2 4 3 2 7 3 8 6 9 0 5 6 0 7 6 1 8 7 9 3 9 8 5 9 3 3 0 7 4 9 8 0 9 4 1 4 4 5 0 4 5 6 1 0 0 1 7 1 6 3 0 2 1 1 7 9 0 2 6 7 8 3 9 0 4 6 7 4 5 8 0 7 8 3 1]
教師データ:
[5 0 4 1 9 2 1 3 1 4 3 5 3 6 1 7 2 8 6 9 4 0 9 1 1 2 4 3 2 7 3 8 6 9 0 5 6 0 7 6 1 8 7 9 3 9 8 5 9 3 3 0 7 4 9 8 0 9 4 1 4 4 6 0 4 5 6 1 0 0 1 7 1 6 3 0 2 1 1 7 9 0 2 6 7 8 3 9 0 4 6 7 4 6 8 0 7 8 3 1]
・2層にしただけでこんなにうまく行くものなのか。なんだか面白いな。
・もう少しMNISTで遊んでみるか。
2026.02.24 15:40
MNISTの準備
・朝からちょっと頭痛がして全身がだるい。
・とりあえず気力でMNISTの手書き画像認識の下調べ。
・結局、あまりたいしたことはなかった。要するに画像データとそのデータの答え(ラベル:0〜9の数値)のファイルがあって、画像データの先頭16バイトとラベルの先頭8バイトがヘッダ。
・で、その後は画像データが28x28(1画素が1バイトの濃淡データ)、ラベルは1バイトで0〜9の値を示しているだけ。
・で、学習用のデータが6万セット、本番用のデータが1万セット用意されている。
・もちろん、使い方は自由なので、学習用のデータの先頭1000個で学習して次の1000個を学習結果の評価用としても良いわけだ。
train-images-idx3-ubyte.gz(6万セットの画像)
train-labels-idx1-ubyte.gz(6万セットのラベル)
t10k-images-idx3-ubyte.gz(1万セットの画像)
t10k-labels-idx1-ubyte.gz(1万セットのラベル)
2026.02.23 06:57
画像認識に発展させてみようか
・さて、せっかく作ったのでもうちょっと遊ぶ。
・簡単な画像認識というのか、手書き文字認識くらいはできるんだろうか。
・今のプログラムではたとえば[4,8,3]というリストを与えればとやれば4入力3出力で入力層が8個、出力層が3個のネットワーク、[4-8-5-3]なら、入力と出力の間にニューロン5個の隠れ層が1層構築されるという具合で結構いろいろな形を作って遊べる。
・ということで、出力をワンホット化して、3x3の画像の分類をさせてみる。まぁ、とりあえず4-8-2で、"|"と"ー"のパターンという単純なもの。正解は"[0,1]"と"[1,0]"でやってみると100回もしないうちに収束。
・それならば・・・とちょっと意地悪して実数の乱数で3x3のパターンを3つ作ってこれを同じように分類。更に6個、12個と作ってこれを3分類させてみたけど、割と良い感じで収束する。
・つまり、これって人間の目にはランダムパターンにしか見えないけど、ニューラルネットは数字として認識できているということだな。なんとなく暗号みたいに使えそうだな。
・超有名なMNISTだと28x28で、784点あるのか。訓練用データ6万個を一気に始末するのはさすがに大変かと思ったけど784×60,000=47,040,000。まぁ44M程度という感じか。1データ4バイト実数にして176Mbytes。メモリ量的には思ったほど大したことないけど、これを行列演算に使うとなったらやはり大変だろうしな。まぁ100個なり1000個なりごとに分割して学習させる感じかな。
2026.02.22 07:51
XOR対応であれこれお試し
・XORは実はそこそこ厳しいものらしいので、しばらくこれで遊んで見ることに。
・LayerStruc=[2,8,4,1]みたいな感じでニューロンのレイヤ構成を自由に作れるように書き換えて、レイヤ構成を変えてみたり、初期値を変えてみたりして試してみている。
・とりあえず2-4-4構成でウェイトを-0.5〜+0.5の一様乱数、バイアスの初期値を0.2程度にして活性化関数をLeaky ReLUにしてみたらこんな感じでサクッと落ち着くことが多くなった。
・一般的には0を中心に正規分布させたほうが良い結果が得られやすいようだけど、XORに関してはそうもいかないのかな?
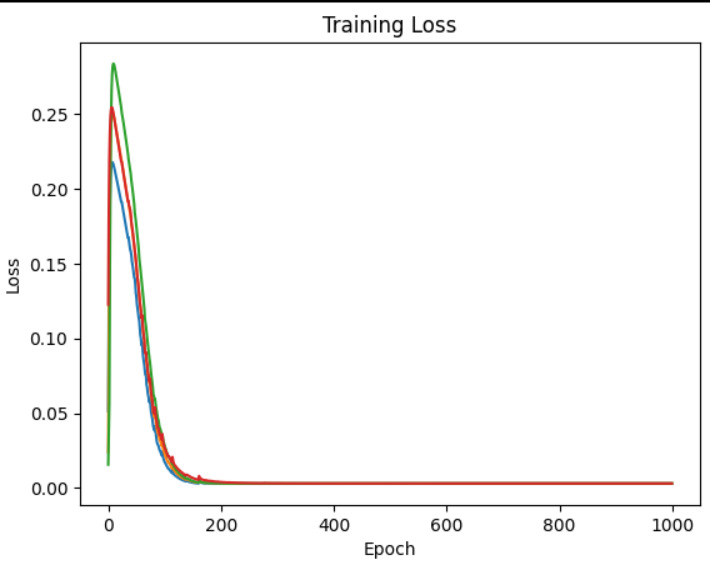
2026.02.21 13:30
2層でXORができた
・さて、なんとなく1層を任意の入力点数、任意のニューロン数で作ることができるようになったので、2層…2段カスケード接続したらどう?というのをやってみる。
1層目が2入力のニューロン4個、2層目が4入力のニューロン4個。で教師データは同じものを与えて同時に教育してみる。ウエイトやバイアスの初期値は乱数なので、4回分同時にチェックする格好。
で、最終段の偏差の自乗がどうなるのかを見てみたのがこのグラフ。上が1層にしたとき。圧倒的な収束の速さだな。
・調子に乗ってXORをやらせてみたら収束したりしなかったり…さて、何が悪いのかな。
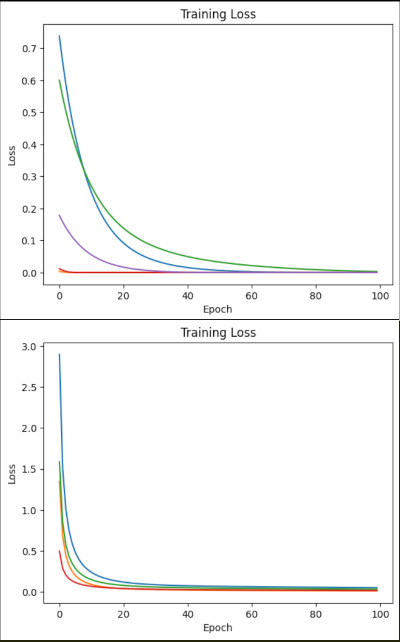
・というところでGCCへのお問い合わせなどもしていろいろいじっていたらXORでも収束するようになってきた。乱数をstandard_normal、つまり0を中心にした正規分布乱数にして、Learning Rateもちょっといじったり。更に1層目のニューロン数を8個に増量。これが一番効いたようだ。XORを教師データとして入力して誤差(前回のは偏差の自乗をグラフにしたけど、これは符号付き)の変化を撮ってみたらこんな感じ。繰り返しやってみるとだいたい500回くらいで収束する。実務的にはこの収束した状態を見て学習済みとして推論用のパラメータにすれば良いんだろうな。
・この学習過程で時々発振というのかリンギングを起こしたような波形が出てくるのが面白いところ。フィードバックがかかっていて、位相が180度反転してループゲインが1未満ならこういう減衰振動になる。
・電子回路ならここでダンピング抵抗を入れたりフェライトビーズを入れたりする感じかな。
・GCCにお尋ねしていたら、AIの世界でもこうした現象を抑制するフィルタみたいな式を入れ込むことが実際に行われることがあるらしい。いろいろつながってるな。
2026.02.20 22:59
ぼちぼちと
・20日ということで、ちょっと現金をおろして記帳。ついでにキャッシュレス関係にチャージもしておく。
・ということで書いたついでにバックプロパゲーションの処理部分を独立させて、多層化しやすそうな構造に書き換えておく。
・なんとなく頭の中もプログラムも整理されてきたな。
・太田光が首相に対して「消費税減税ができなかったらどうするのか」と訪ねたら「意地悪な質問ですね」と答えたとかいうことをラジオで取り上げていた。
・「普通な質問なのに・・」と言ったあとに沖縄の知事が地元の案件について同じような質問を受けたときに「できなければ腹を切る」と言ったとかいうことを持ち上げて「覚悟が聞きたかった]などと言っていた。
・絶対うそだろう。この質問は「言質を取ろう」という悪意ある質問であろう。それは、この質問がどのような答えを期待しているのかを考えればすぐわかることだ。「できないかもしれない]といえば無責任だと非難し、「できなければ辞職だ]と「覚悟」とやらを語れば後日成立が遅れたり先送りになったときに「辞職だと言ったくせに」といって非難する。そのための材料をを得ようとしているのだろうとしか考えようがない。
・「違う。単に覚悟の程を聞きたかっただけだ」というなら「後日これをネタに非難することがないと言い切れるのか。もし非難するような言動をしたらどう責任を取るのか」と尋ねればきっと、「首相という立場とは重さが違う」とか「ジャーナリズムは・・・」とか言って逃げるのだろうな。
2026.02.19 22:27
バックプロパゲーションでフィードバックする値は
・だいぶ形になったので、多層化を考えていくことにする。
・となると、今までニューロンクラスの中でやっていた教師データとの比較は外に出すことになるわけか。
・ところで、今のプログラムだと入力のデータパターンについて同時演算させている。今は2入力ANDを扱っているので、[00][01][10][11]のそれぞれごとに初期値の違うN個のニューロンがどういう値を出力するのかを4行N列の行列で得ているという具合。
・ここからバックプロパゲーションで戻す値はというと、セルごとの入力点数(この場合なら2)にセルの数を掛けた分の入力端子があるようなイメージになって、それをそれぞれのニューロンが持っているバックプロパゲーションでフィードバックする値をウェイト値で按分したもの・・・だから2N行1列の行列を得るのか?いや、でもそれはなんかおかしいのではないか。
・と、考えていてなんのことはないと気付く。それぞれのニューロンの入力端子をA,Bとしたとき、全部のニューロンの入力端子A同士、B同士がつながったよう状態になっているので、フィードバックする値は全部のニューロンのフィードバック値を足したものになるはず。ってことは普通に行列演算でいける。
2026.02.18 19:27
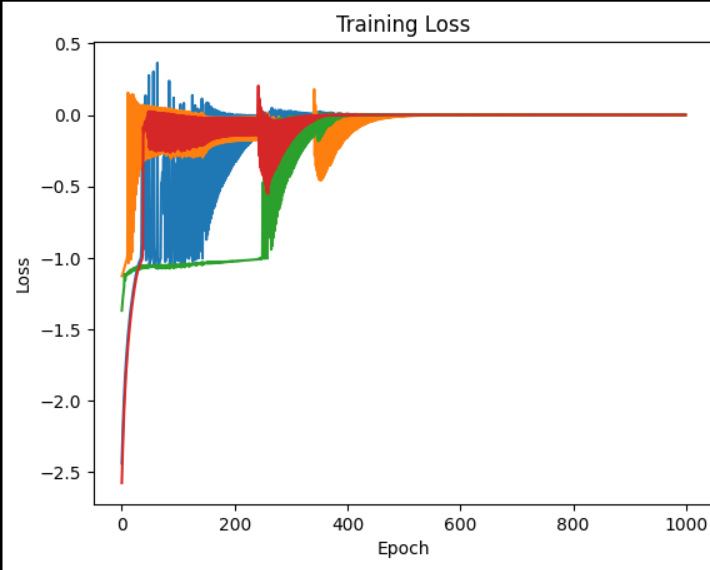
セルを4つにしてみる
・間違っていたところがわかった。うっかりnp.sum()を残していたために2個の入力に同じ値がフィードバックされてしまっていた。
・修正してみたら良い感じ。ついでなので、セルを4つに増やして改めて学習の進み方を見た。4つのセルの学習の進み方を見ると面白いように同じところにおちついていく。
・そういうものかな。
2026.02.17 11:36
ニューロン1個で少し遊ぶ
・とりあえず2入力のニューロン2個を並列配置して行列使って同時進行させてみる。
・要は[[0,0],[0,1],[10],[11]]の二次元行列を入力、[[0,0],[0,0],[0,0],[1,1]]を正解データ(実際には[[0],[0],[0],[1]]をブロードキャストで拡張するけど)として、出力として[[0,0],[0,0],[0,0],[1,1]]が得られるかどうかというところ。
・実際には浮動小数点データで得られるのだけど。なぜイマイチ収束しないんだろうと思いながら、コードの間にprint(f"...")なのを挟んでいく。printf()ではなくprint(fというあたりにちょっと感じるものも。
・見にくいのでnp.where(x>0.5,1,0)を使って1/0に変換したらそれなりになった。なんとなく目がくらんでいただけで、結構それなりだったのか。
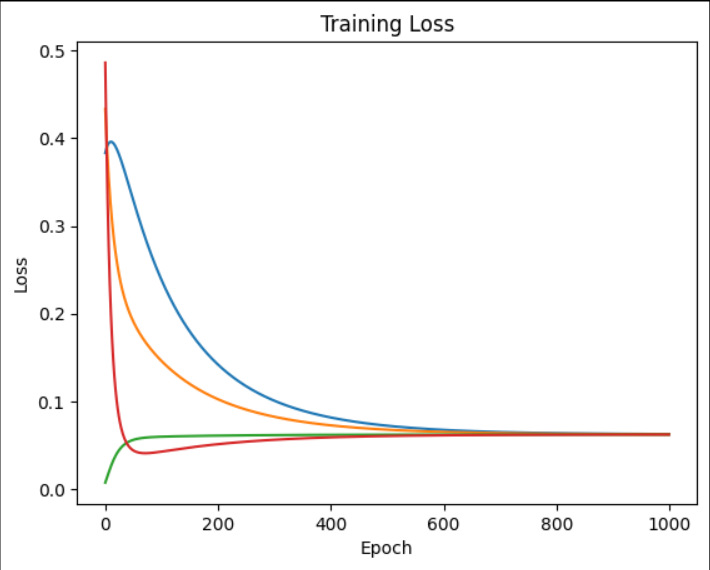
・学習の回数と教師データとの誤差をグラフかすることにして、初期値やら学習率(LR)やら活性化関数(Leaky ReLUにしてみたけど)にちょっと細工をしてみたりするといろいろ面白い。
・学習を0.001からドンドン・・と増やしてみたのがこれ。
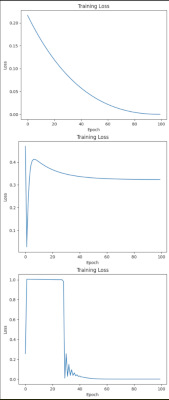
で、まぁこれは一例でやるたびにグラフの形状は大きく変わる(初期値を乱数にしているからでもあるけど)けど、大まかにはLRを大きくすると学習は早く進むようだけど、暴れやすくなる。オーバーシュートやアンダーシュート、リンギング波形みたいなものも出てきたりして、なんとなくハード屋さんの世界とも通じるものを感じたり。
・だとすると、バックプロパゲーションにLPFなんか入れて「誤差が大きく変わったら少し抑える」とかすると暴れにくくなるのかな?
・・・・・
・2/18追記:と思ったのだけどプログラムでなんか変なところがあった。リトライだな。